TL;DR
Abstract
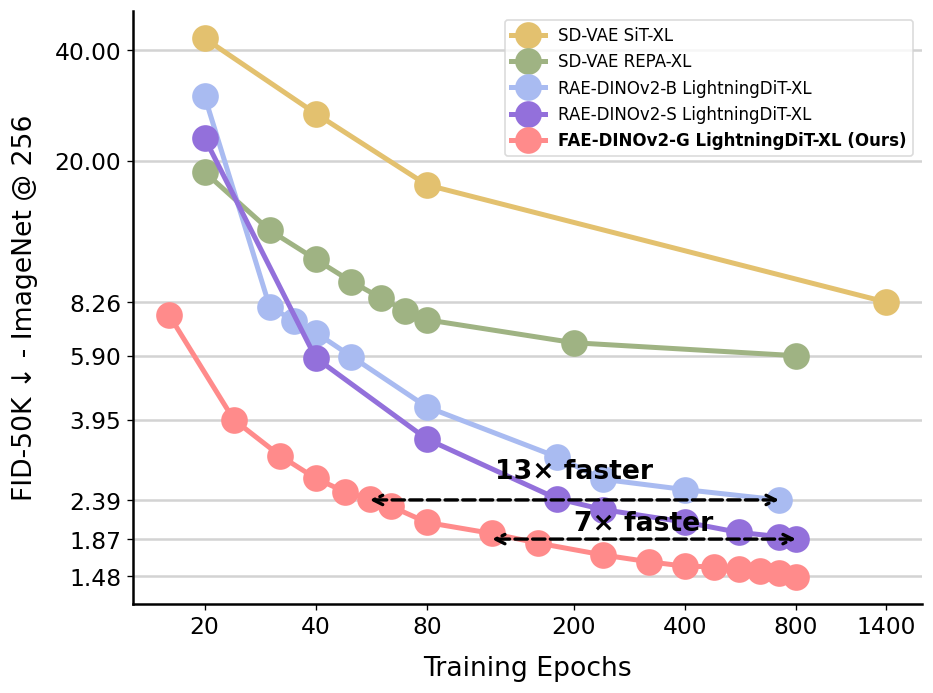
Visual generative models (e.g., diffusion models) typically operate in compressed latent spaces to balance training efficiency and sample quality. In parallel, there has been growing interest in leveraging high-quality pre-trained visual representations, either by aligning them inside VAEs or directly within the generative model. However, adapting such representations remains challenging due to fundamental mismatches between understanding-oriented features and generation-friendly latent spaces. Representation encoders benefit from high-dimensional latents that capture diverse hypotheses for masked regions, whereas generative models favor low-dimensional latents that must faithfully preserve injected noise. This discrepancy has led prior work to rely on complex objectives and architectures. In this work, we propose FAE (Feature Auto-Encoder), a simple yet effective framework that adapts pre-trained visual representations into low-dimensional latents suitable for generation using as little as a single attention layer, while retaining sufficient information for both reconstruction and understanding. The key is to couple two separate deep decoders: one trained to reconstruct the original feature space, and a second that takes the reconstructed features as input for image generation. FAE is generic; it can be instantiated with a variety of self-supervised encoders (e.g., DINO, SigLIP) and plugged into two distinct generative families: diffusion models and normalizing flows. Across class-conditional and text-to-image benchmarks, FAE achieves strong performance. For example, on ImageNet 256x256, our diffusion model with CFG attains a near state-of-the-art FID of 1.29 (800 epochs) and 1.70 (80 epochs). Without CFG, FAE reaches the state-of-the-art FID of 1.48 (800 epochs) and 2.08 (80 epochs), demonstrating both high quality and fast learning.
Method
Overview figure from the paper — see the linked paper for full details.
Key Contributions
Coupling two deep decoders: one reconstructs the original feature space, while a second turns the reconstructed features into images.
A one-attention-layer adapter that turns understanding-oriented features into low-dimensional, generation-ready latents.
Generic across encoders (DINO, SigLIP) and generative families, reaching SOTA ImageNet-256 FID (e.g. 1.48 without CFG).
BibTeX
@inproceedings{gao2025one,
title = {One Layer Is Enough: Adapting Pretrained Visual Encoders for Image Generation},
author = {Gao, Yuan and Chen, Chen and Chen, Tianrong and Gu, Jiatao},
booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Findings},
year = {2026}
}