Projects
The TARFlow family
A connected line of work taking normalizing flows from a single architecture to a scalable, general-purpose generative paradigm. Tiles are sized by significance.
A research program reviving normalizing flows as scalable, end-to-end, likelihood-based generators — across images, video, language, and unified multimodality.
A connected line of work taking normalizing flows from a single architecture to a scalable, general-purpose generative paradigm. Tiles are sized by significance.
One invertible network, one likelihood objective — a single backbone for images, video, language, and unified multimodality.
Built on the Transformer Autoregressive Flow (TARFlow), this line of work shows that normalizing flows — long overshadowed by diffusion models — are in fact capable generative models that scale. By keeping the model an exact, invertible, maximum-likelihood normalizing flow while borrowing the architecture of autoregressive Transformers, these invertible models reach high-resolution image synthesis, video world models, continuous-space language modeling, and unified multimodal generation.
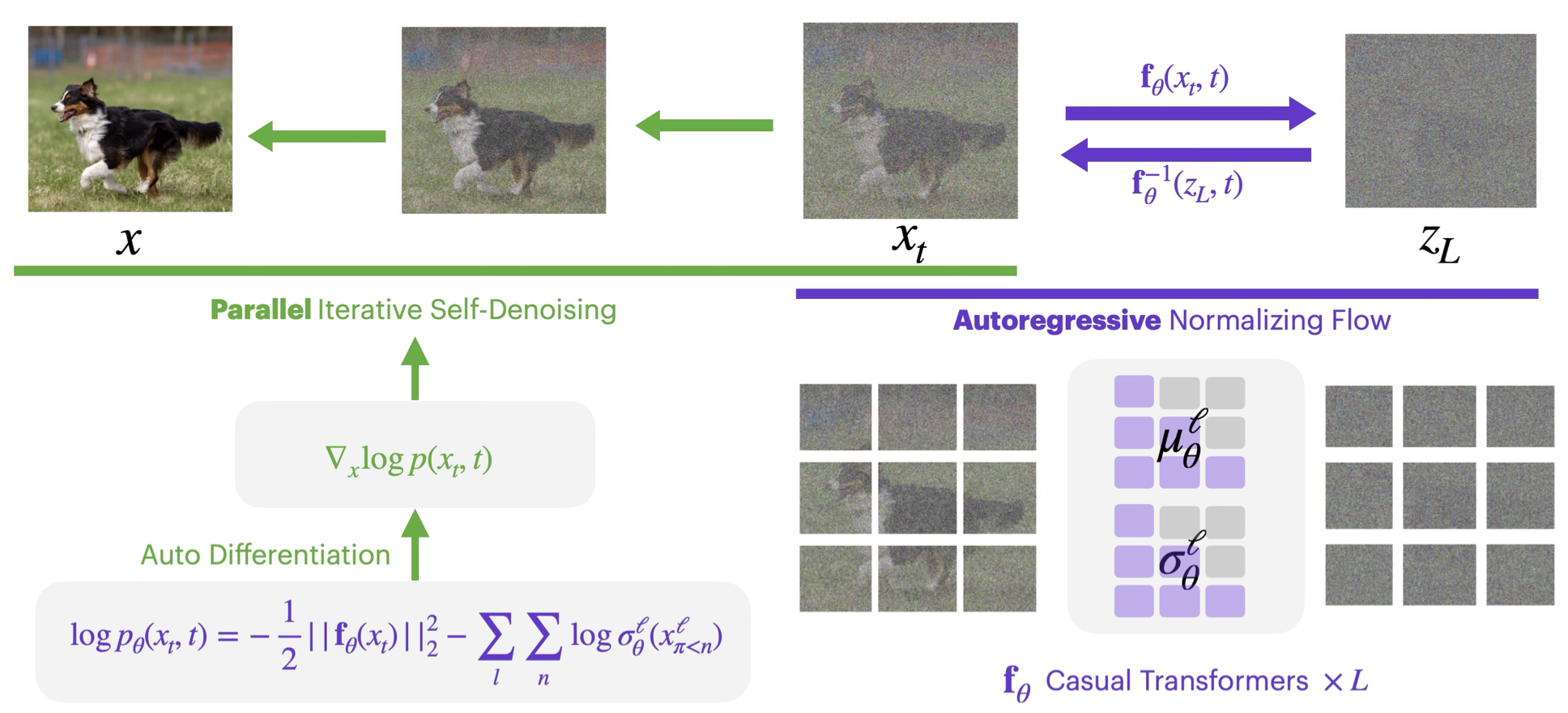
A normalizing flow is a single invertible network f that maps data x to simple Gaussian noise z — and runs backward to map it home.
Trained by exact maximum likelihood — one clean objective. No ELBO, no noise schedule, no discretization.
x ↔ z is exactly reversible — encoding and generation share the very same network and weights.
x stays in ℝd throughout — no codebook, no quantization. The same machinery LLMs already run at scale.
Normalizing flows were always there — RealNVP, Glow, MAF/IAF, Flow++ — and always kept exact likelihood, but lost ground to GANs and diffusion on sample quality. The Transformer revival changes the verdict: TARFlow gets diffusion-level samples from a stand-alone flow, and the work below scales that one backbone to new modalities.
Classical flows leaned on hand-designed coupling layers — expressive enough for densities, but their samples stayed behind GANs and diffusion. The architecture, not the principle, was the bottleneck. Three ingredients close the gap:
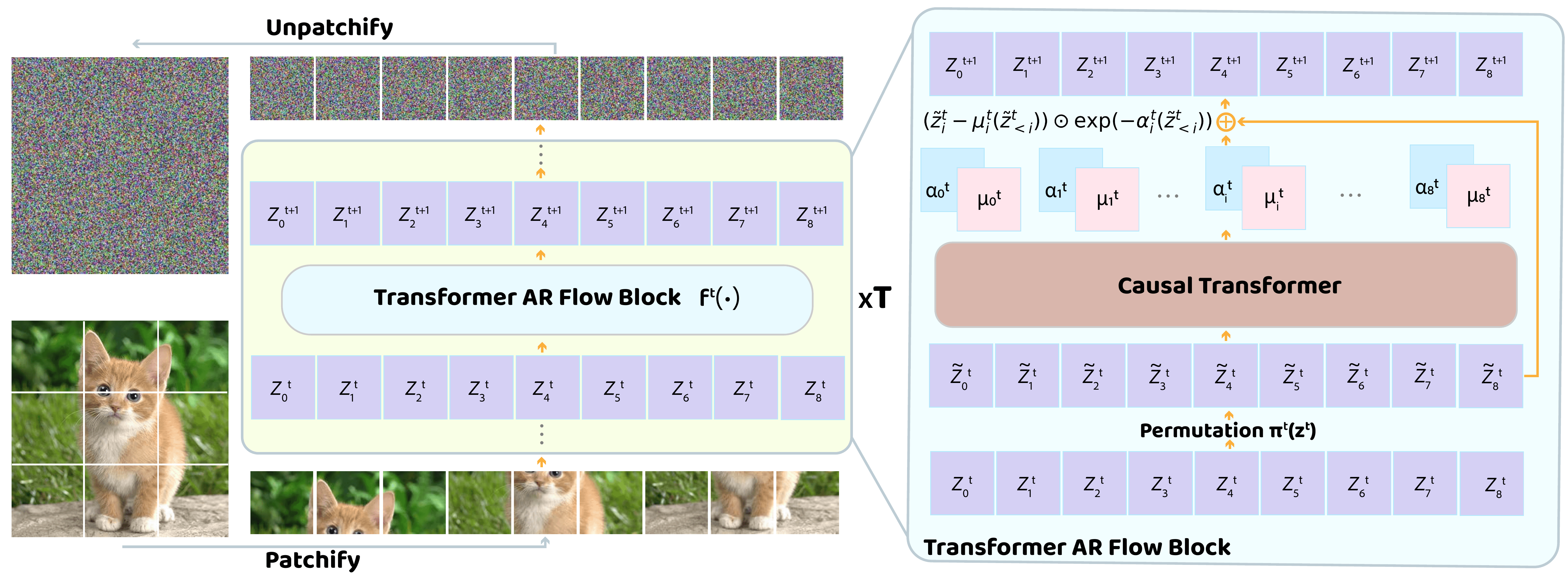
Then: shallow stacks of affine coupling / 1×1 convs — limited capacity, hard to scale.
Now: one deep autoregressive Transformer block carries most of the capacity (acting like a language model over tokens), plus a few cheap shallow blocks with alternating scan direction for local detail — parallelizable in the inverse.
Then: exact MLE on clean data overfits high-frequency detail and yields noisy samples.
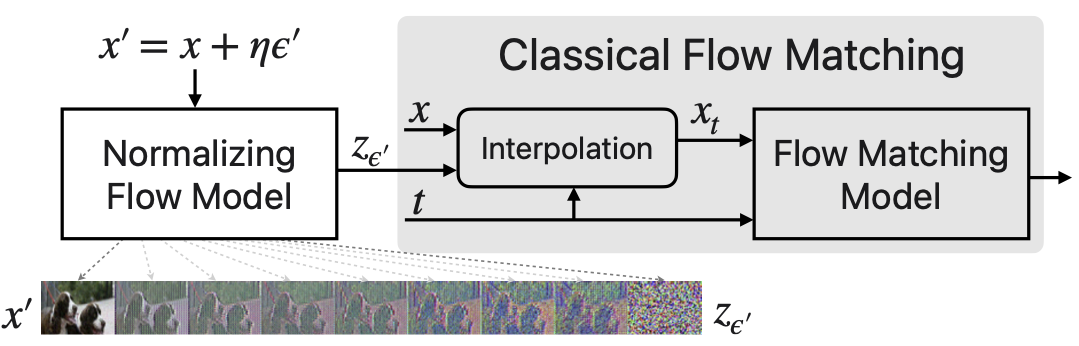
Now: Gaussian noise augmentation during training, paired with a small post-hoc denoiser at sampling — the same trick that lets the flow produce clean, sharp images while staying an exact-likelihood model.
Then: no quality/diversity knob — flows generated unconditionally from the prior.
Now: guidance applied in the deep block (a new recipe for flows) trades diversity for fidelity, just like diffusion — pushing samples to diffusion-level quality from one MLE objective.
The normalizing-flow lineage this program builds on — exact-likelihood models that stayed behind diffusion on sample quality, until the Transformer turn.
NICE: Non-linear Independent Components Estimation
Density Estimation using Real NVP
Improving Variational Inference with Inverse Autoregressive Flow
Masked Autoregressive Flow for Density Estimation
Glow: Generative Flow with Invertible 1x1 Convolutions
Flow++: Improving Flow-Based Generative Models with Variational Dequantization and Architecture Design
Diffusion-level samples from a stand-alone flow — where the program begins.
Every paper in the program, newest first. Switch to Related to see work from the wider community.