TL;DR
Abstract
Diffusion-based models decompose sampling into many small Gaussian denoising steps -- an assumption that breaks down when generation is compressed to a few coarse transitions. Existing few-step methods address this through distillation, consistency training, or adversarial objectives, but sacrifice the likelihood framework in the process. We introduce Normalizing Trajectory Models (NTM), which models each reverse step as an expressive conditional normalizing flow with exact likelihood training. Architecturally, NTM combines shallow invertible blocks within each step with a deep parallel predictor across the trajectory, forming an end-to-end network trainable from scratch or initializable from pretrained flow-matching models. Its exact trajectory likelihood further enables self-distillation: a lightweight denoiser trained on the model's own score produces high-quality samples in four steps. On text-to-image benchmarks, NTM matches or outperforms strong image generation baselines in just four sampling steps while uniquely retaining exact likelihood over the generative trajectory.
How it works
Can fast generative models still be likelihood-based? Excited to share our new work from Apple MLR — Normalizing Trajectory Models (NTM): a step toward high-quality few-step generation with exact trajectory likelihood, powered by normalizing flows.

Diffusion and flow-matching models typically generate through many small steps, where simple denoising transitions are a reasonable approximation. But when we compress generation into only a few coarse steps, the reverse transitions become much more complex.

Most fast generators rely on distillation, consistency training, or adversarial / distribution-level objectives. They produce strong samples, but often move away from the likelihood-based formulation that made diffusion and flow models principled and scalable.

We take a different view: few-step generation can be trajectory density modeling. Instead of only learning a fast sampler, we learn a likelihood-based model over the full generative trajectory, so fast generation stays tied to an explicit probabilistic objective.

Concretely, NTM models each transition p(xₛ|xₜ) with an expressive conditional normalizing flow. This gives more flexibility than simple Gaussian denoising — enabling complex few-step transitions while keeping exact likelihood tractable over the full trajectory.
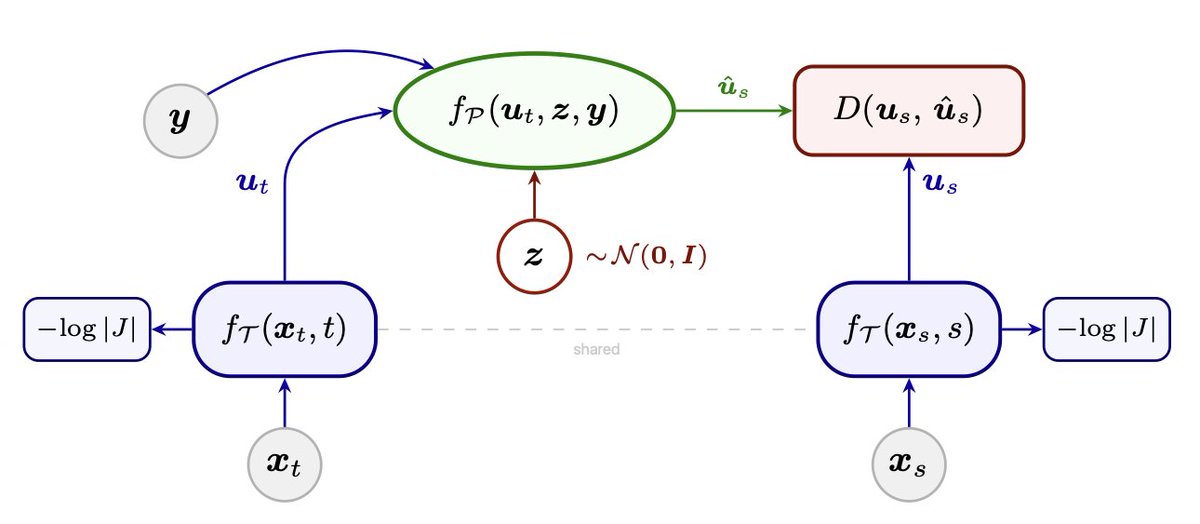
Architecturally, NTM combines shallow invertible autoregressive transporters with an image-level predictor. This allows training from scratch or initializing from a pretrained flow-matching model, then refining it into a likelihood-based trajectory model for fast generation.
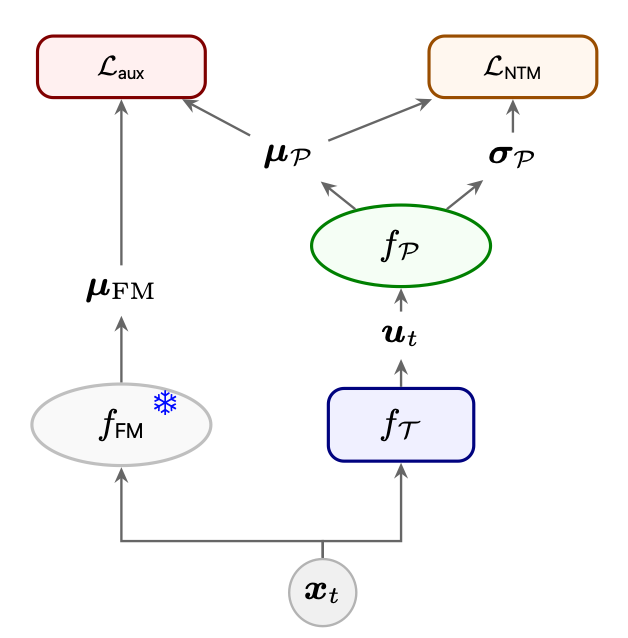
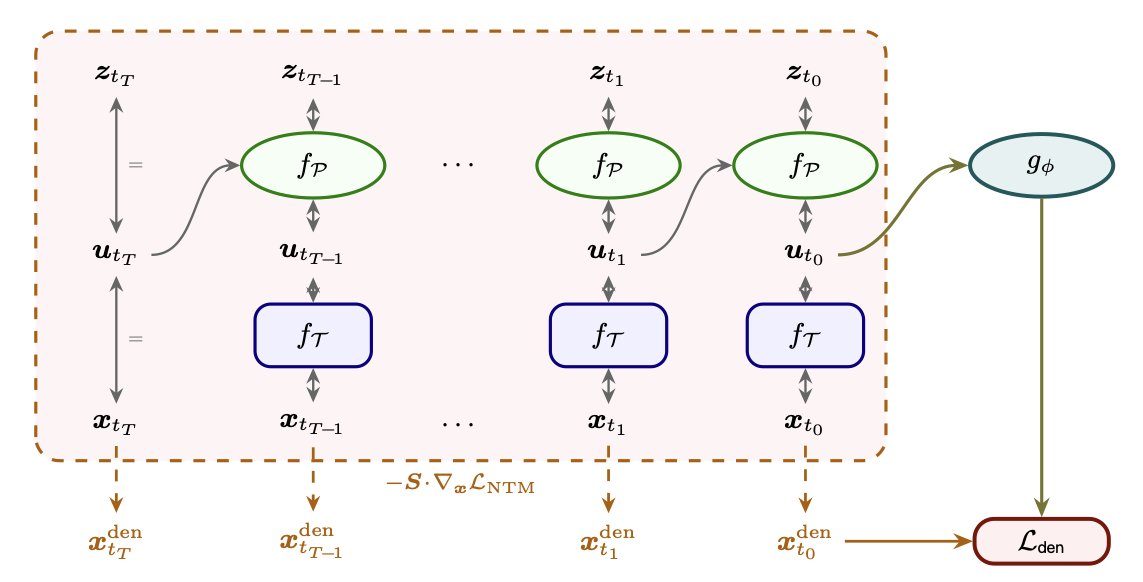
Because NTM has exact trajectory likelihood, it provides direct and stable trajectory-score / denoising targets. We use them to train a lightweight denoiser, so sampling can bypass the costly shallow AR flow blocks while keeping NTM's trajectory knowledge.
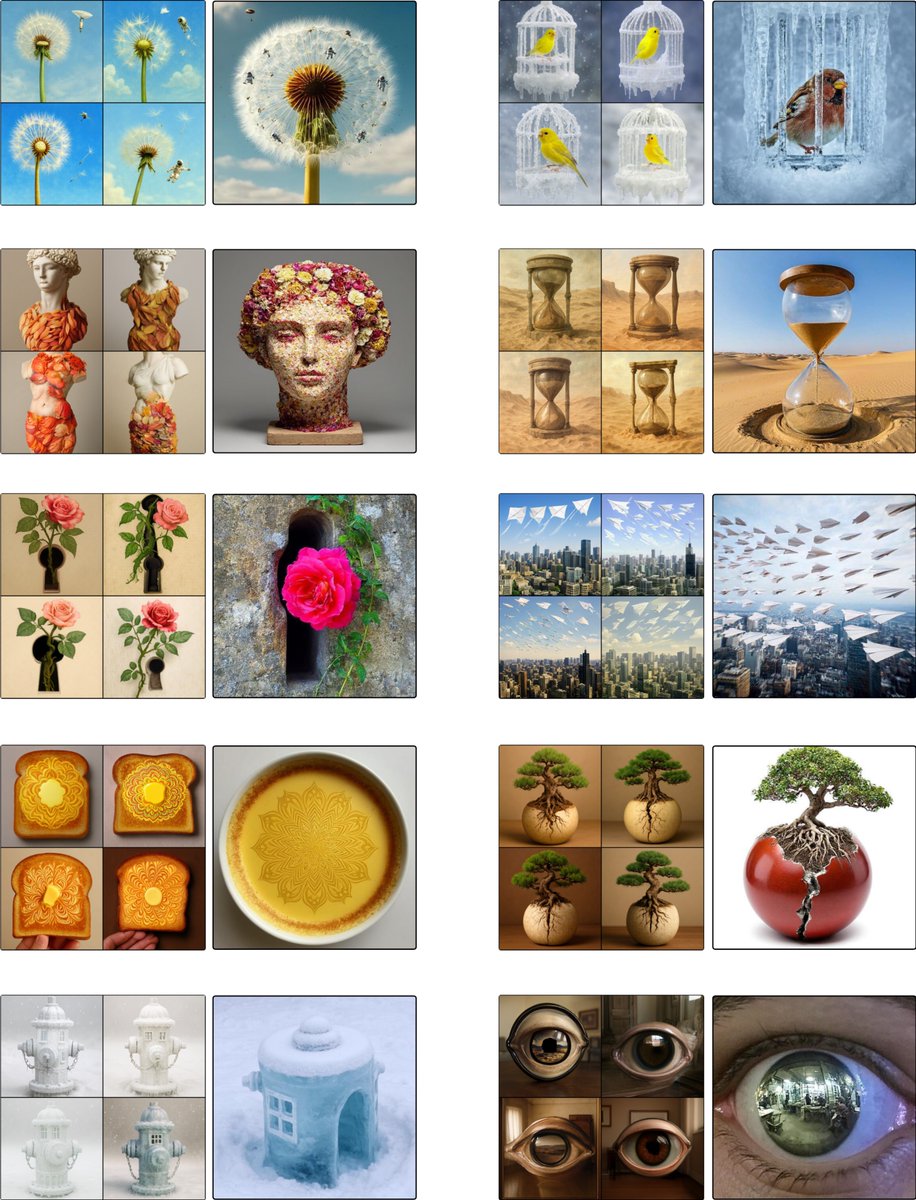
Empirically, NTM shows that likelihood training and fast generation can coexist: strong few-step text-to-image results — from scratch or initialized from pretrained flow-matching models — plus a self-distilled 4-step denoiser derived from NTM's stable trajectory targets.
I'm very excited about this direction: expressive, likelihood-based modeling for fast generation — and, more broadly, as a potential foundation for tractable world models. Huge thanks to the amazing collaborators who made this work possible.
BibTeX
@article{gu2026normalizing,
title = {Normalizing Trajectory Models},
author = {Gu, Jiatao and Chen, Tianrong and Shen, Ying and Berthelot, David and Zhai, Shuangfei and Susskind, Josh},
journal = {arXiv preprint arXiv:2605.08078},
year = {2026}
}