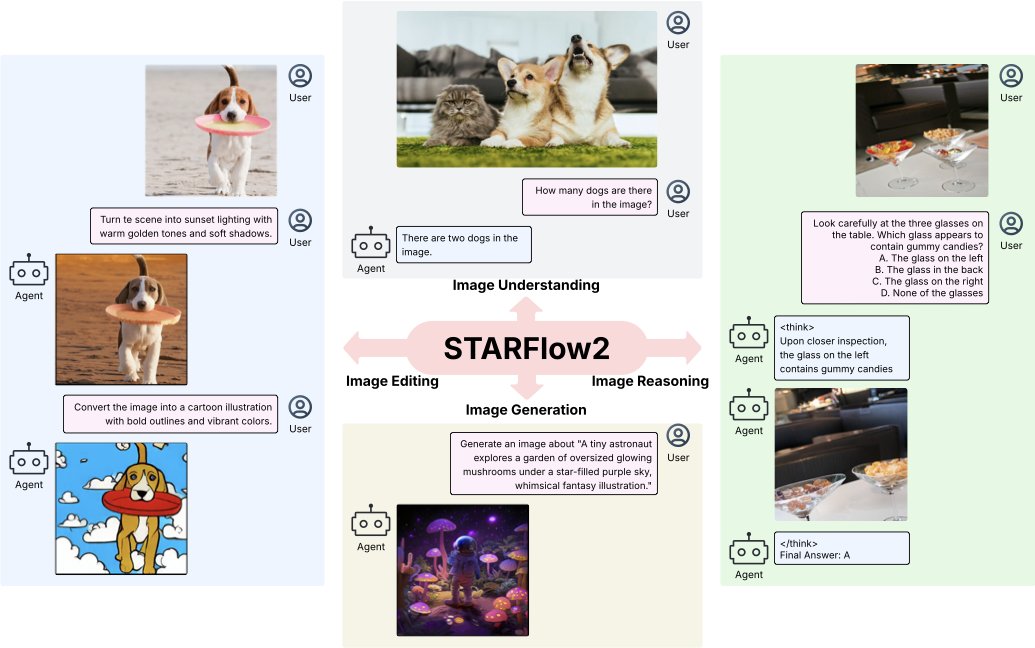
TL;DR
Abstract
Deep generative models have advanced rapidly across text and vision, motivating unified multimodal systems that can understand, reason over, and generate interleaved text-image sequences. Most existing approaches combine autoregressive language modeling with diffusion-based image generators, inheriting a structural mismatch between causal text generation and iterative visual denoising. We observe that autoregressive normalizing flows are autoregressive Transformers--sharing the same causal mask, KV-cache mechanism, and left-to-right structure as LLMs--making them the most natural paradigm for true unified multimodal generation. We present STARFlow2, built on the Pretzel architecture that vertically interleaves a pretrained VLM stream with a TarFlow stream via residual skip connections, both operating under the same causal mask. Combined with a deep-shallow flow design and a unified FAE latent space, STARFlow2 enables cache-friendly interleaved generation where both text and visual outputs directly enter the KV-cache without re-encoding. Experiments demonstrate strong performance across image generation and multimodal understanding benchmarks, validating autoregressive flows as a viable foundation for unified multimodal modeling.
How it works
Excited to share STARFlow2 from Apple MLR — 🥨 Bridging Language Models and Normalizing Flows for Unified Multimodal Generation. One model to understand, reason over, and generate continuous images with a single unified autoregressive mechanism.
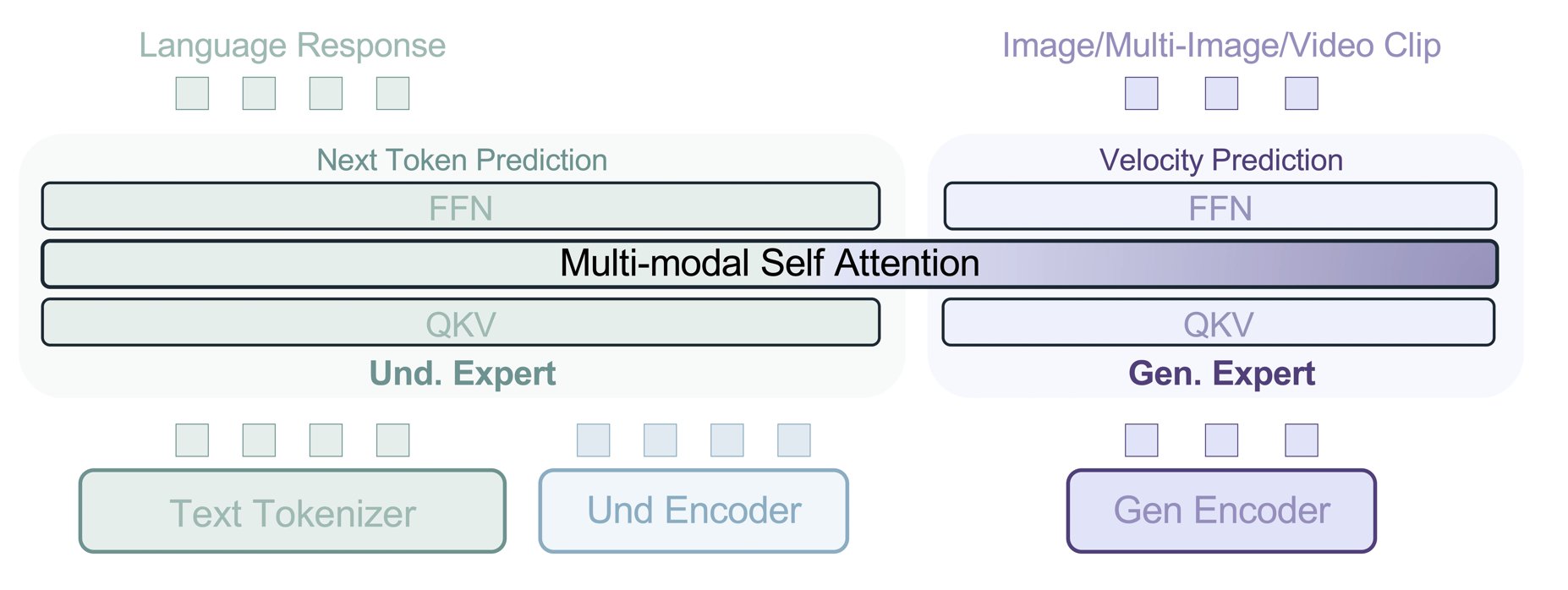
A core challenge in unified models is a structural mismatch: language models decode text causally with a KV-cache, while top image generators rely on iterative full-image denoising. This makes interleaved text-image generation unnatural and often requires re-encoding visual outputs.
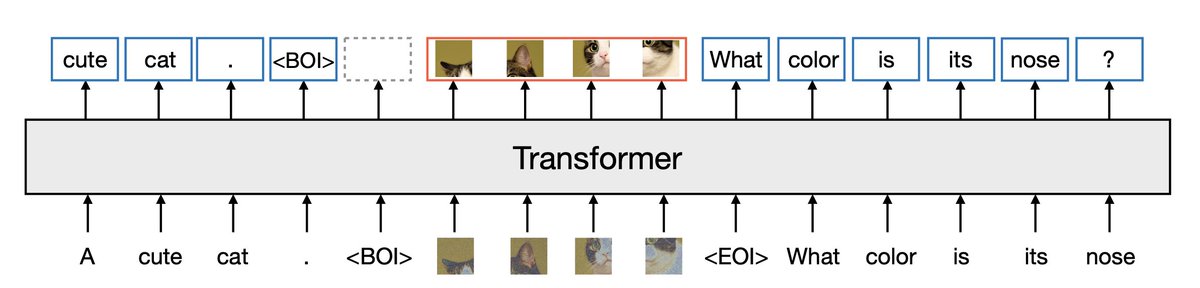
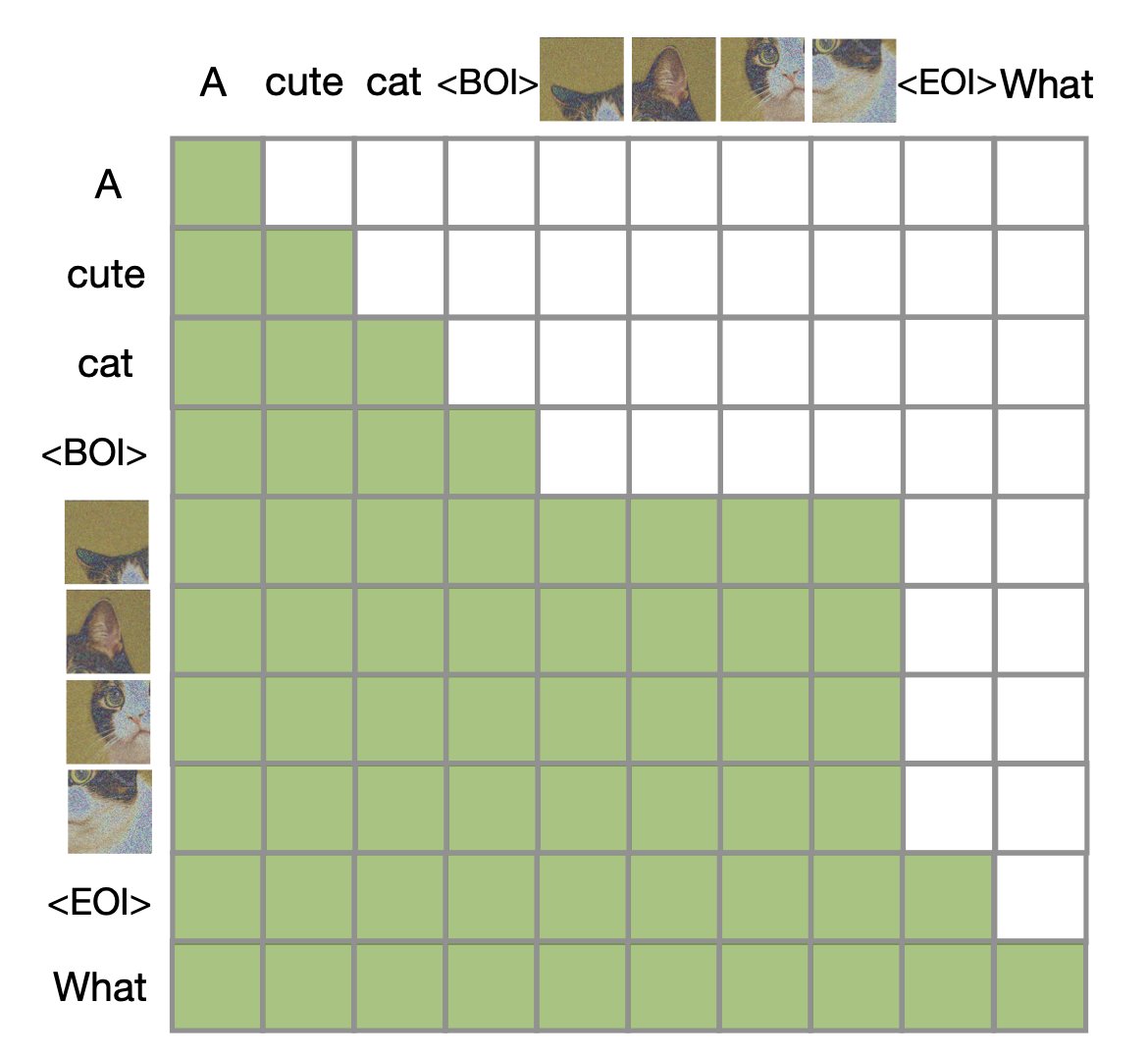
But do we have to use diffusion? Maybe there is a better option — normalizing flows. From our prior work STARFlow, we know normalizing flows can also be causal Transformers: the same causal mask, the same KV-cache, the same left-to-right structure as LLMs.

We propose STARFlow2 as a natural bridge between LLMs and continuous image generation. It supports exact-likelihood training and enables cache-friendly interleaved text-image generation without discrete image tokenization, diffusion loops, or visual re-encoding.
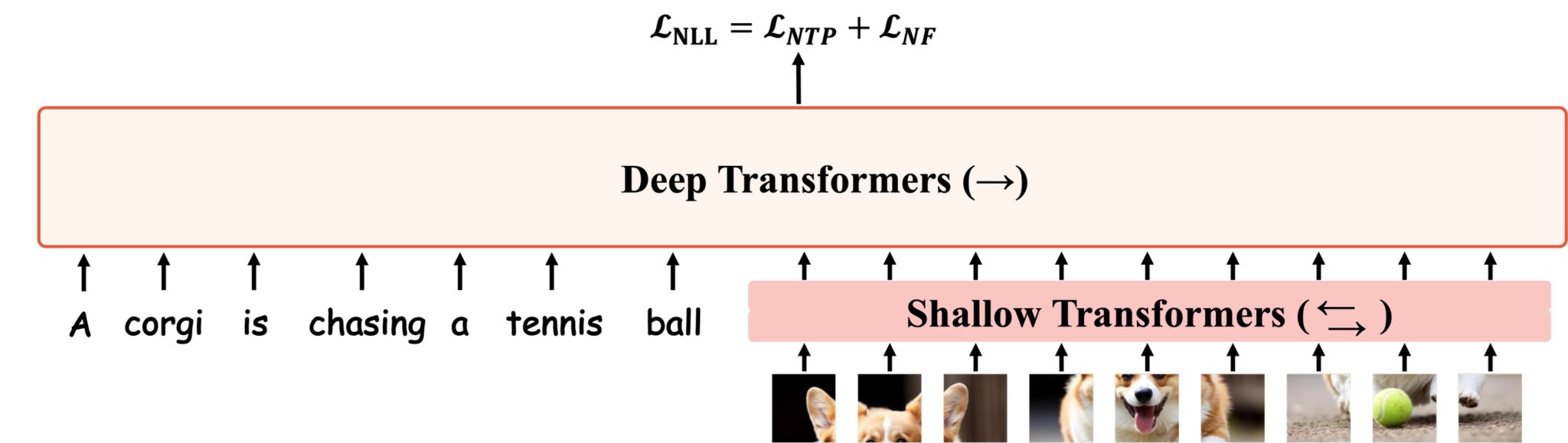
In practice, we introduce the 🥨 Pretzel architecture, which vertically interleaves a frozen pretrained VLM stream with a TARFlow stream through skip connections — preserving strong visual understanding while adding high-fidelity continuous image generation in one model.
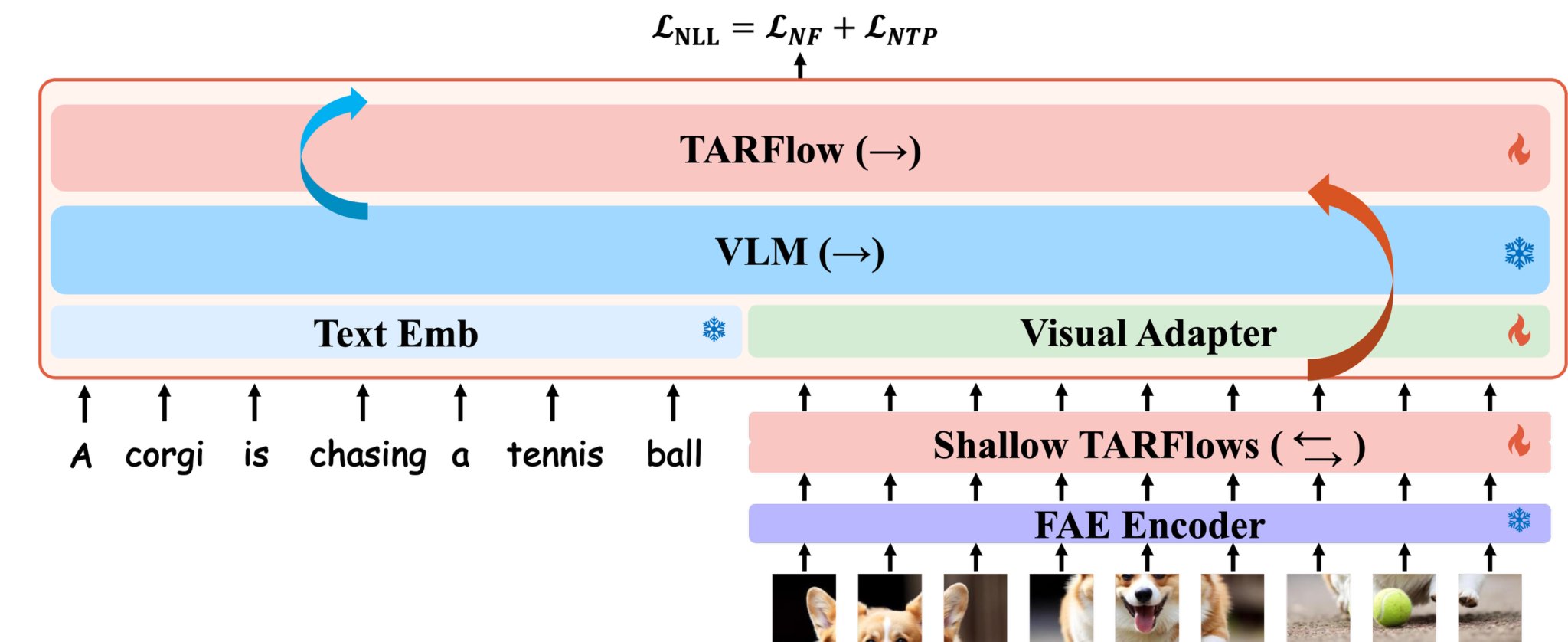
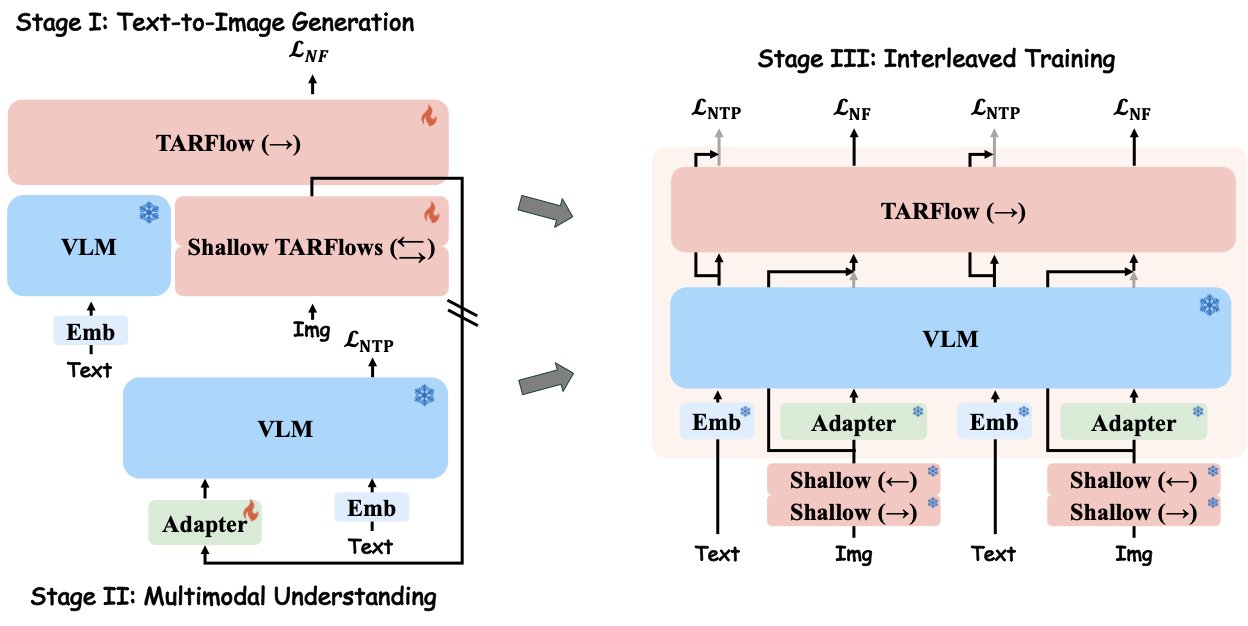
STARFlow2 is trained in three stages: (1) text-to-image pretraining, (2) image-to-text adapter learning, and (3) interleaved joint learning. This staged curriculum avoids disrupting the pretrained VLM while gradually aligning the TARFlow stream for bidirectional text-image interaction.
Experiments show strong image generation while retaining VLM capabilities. Beyond understanding and generation, STARFlow2 also supports image editing and visual reasoning through generated intermediate images — all within the same causal autoregressive framework.


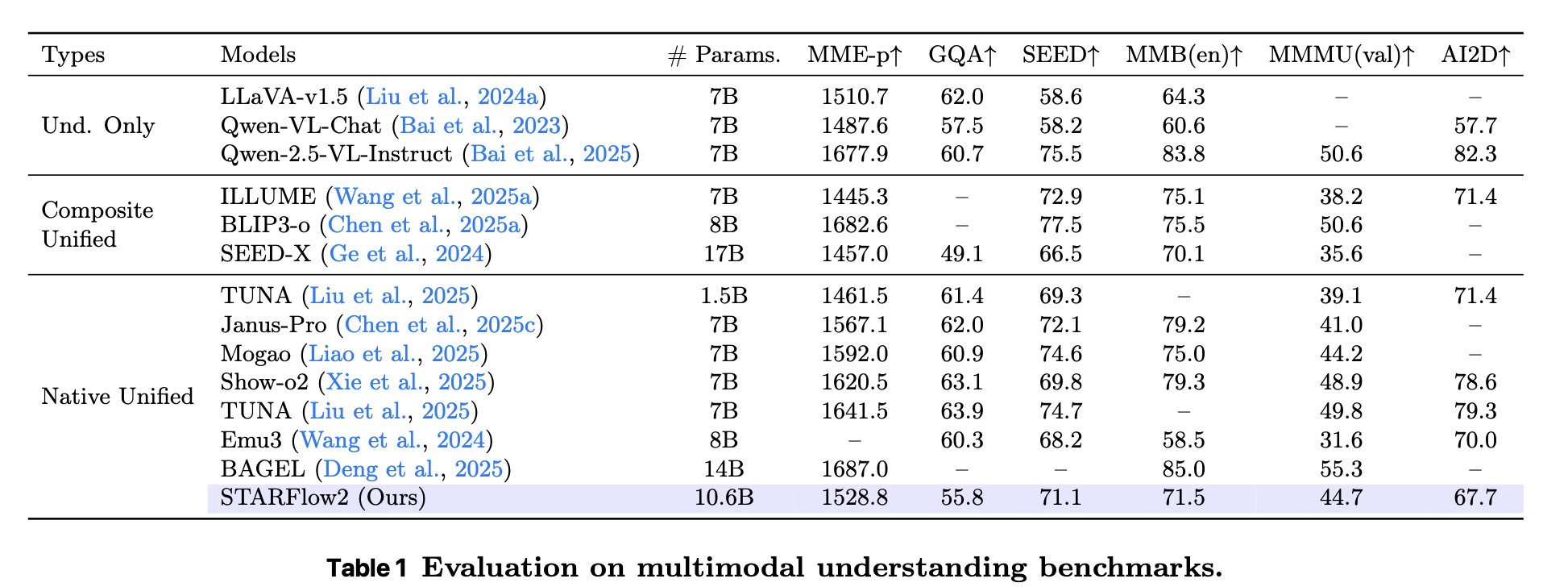
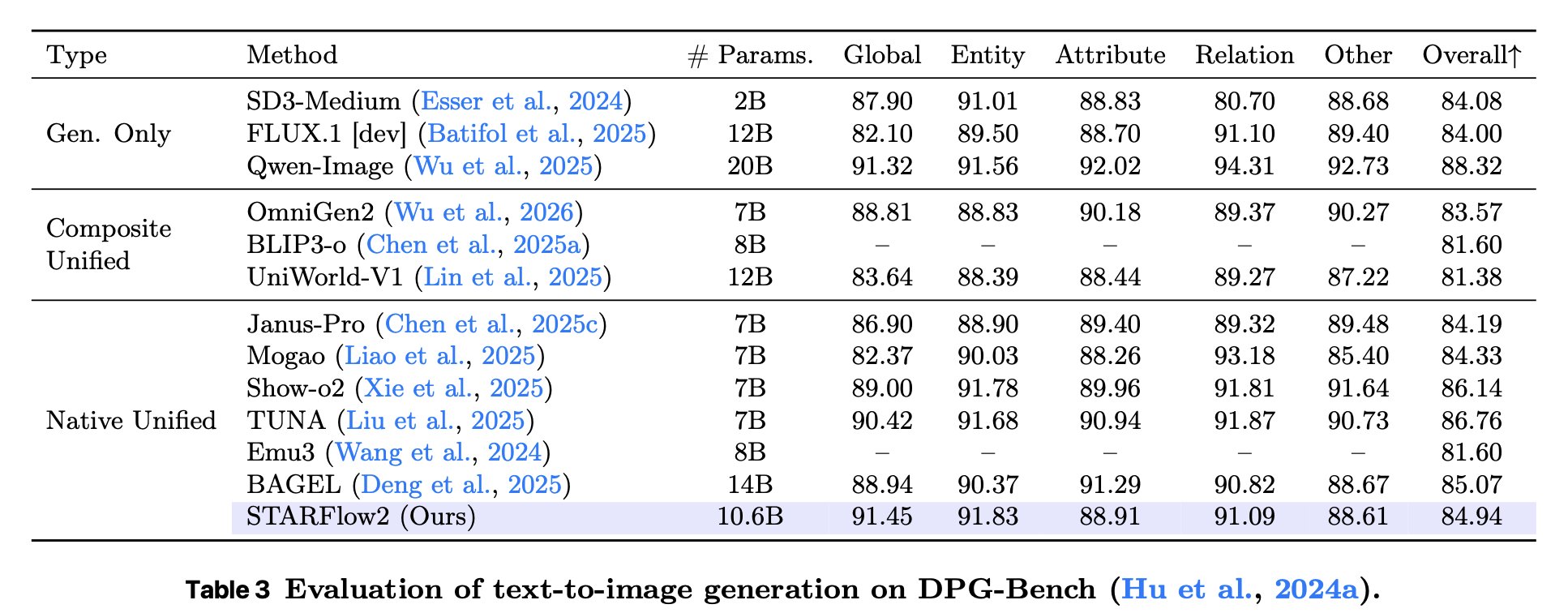
Surprisingly, the standard 🥯 BAGEL (MoT) architecture did not work well for us. The issue was not modality specialization alone, but how to couple two very different computation streams — which led to 🥨 Pretzel and its vertical interleaving with skip connections.

BibTeX
@article{shen2026starflow2,
title = {STARFlow2: Bridging Language Models and Normalizing Flows for Unified Multimodal Generation},
author = {Shen, Ying and Chen, Tianrong and Gao, Yuan and Zhang, Yizhe and Wang, Yuyang and Bautista, Miguel Ángel and Zhai, Shuangfei and Susskind, Joshua M. and Gu, Jiatao},
journal = {arXiv preprint arXiv:2605.08029},
year = {2026}
}